
ε Pulse: Issue #27
Context Engineering👷🏿,Grok 4📒, and a Foundation Model for Tumor Microenvironment 🎗



[LLM/AI for Science et al] 🤖 🦠 🧬
[I]: A Foundation Model for Tandem Mass Spectrometry Data.
Summary
LSM1-MS2 is a self-supervised transformer-based foundation model for tandem mass spectrometry (MS/MS) that enables accurate chemical property prediction, efficient spectral database lookup, and de novo molecular generation using minimal labeled data. The work was published early 2024 by Matterworks.

Technical details
The input to LSM1-MS2 consists of MS/MS spectra, which are tokenized using a custom approach where each peak is represented by concatenated embeddings of integer and decimal parts of m/z values along with binned intensity, projected into a unified space and padded to 64 peaks. Pre-training uses a reconstruction-based masked signal modeling task where 25% of peak tokens are masked and the model learns to predict m/z and intensity values using cross-entropy loss with weighted terms. The architecture is a 16-layer transformer encoder with 16 attention heads and a hidden dimension of 1024. Fine-tuning involves using mean pooled embeddings for downstream tasks. For property prediction, a regression head predicts 209 RDKit descriptors. For spectral lookup, the model embeds paired spectra and aligns cosine similarity of embeddings with the Tanimoto similarity of molecular fingerprints. For generation, a two-step model aligns LSM1-MS2 embeddings with a BERT-style encoder and conditions a GPT-2 decoder to autoregressively generate molecular SELFIES. Outputs include molecular property vectors, nearest-neighbor spectra, or ranked lists of generated molecular structures. LSM1-MS2 outperforms supervised baselines like MS2Prop and cosine similarity in accuracy and speed, particularly in data-limited or out-of-distribution scenarios. It addresses the scarcity of labeled MS/MS data by leveraging a massive corpus of 100 million unlabeled spectra, demonstrating the value of foundation models in metabolomics and chemical discovery.
And what product does a model of this kind unlock?
The LSM1-MS2 model unlocks the creation of advanced software products for researchers in fields like drug discovery and metabolomics. Such a product would function as a comprehensive analysis platform that can take raw mass spectrometry data and rapidly identify known molecules using high-speed spectral lookup, characterize unknown compounds by predicting their chemical properties, and propose potential molecular structures using de novo generation. Ultimately, this could lead to an even more advanced agentic AI system that intelligently guides lab equipment "on-the-fly" during experiments to focus specifically on discovering novel and high-value molecules.
[II]: Noetik: Foundation Models of Tumor Microenvironments.
In a recent essay, Abhishaike Mahajan announces his move to Noetik, a biotech startup building foundation models of tumor microenvironments. But what I find interesting is that he articulates a specific worldview on the intersection of machine learning and biology. Mahajan posits that scaling laws are not working in biology as they have in natural language, suggesting that progress requires scaling across multiple data modalities (genomics, proteomics, imaging, etc.) rather than just increasing the size of unimodal datasets. He also argues that many bio-ML companies focus on problems where they face strong competition from traditional wet-lab methods. Instead, Mahajan believes the most valuable application of ML is on problems so complex and intractable—like understanding cancer immunotherapy failures—that bespoke ML models offer the only real path forward. Finally, he makes a case for moving beyond individual biomolecules to study the larger, systems-level biological phenomena that are clinically relevant.Mahajan explains that he chose Noetik because its R&D strategy directly aligns with these three core beliefs.
The company is building the world's largest multimodal, paired dataset from human tumor biopsies, collecting information across exome sequencing, spatial transcriptomics, and immunofluorescence. This rich, multi-layered data feeds into its primary focus: the profoundly difficult challenge of cancer therapeutics, particularly understanding the varied patient responses to immunotherapy.
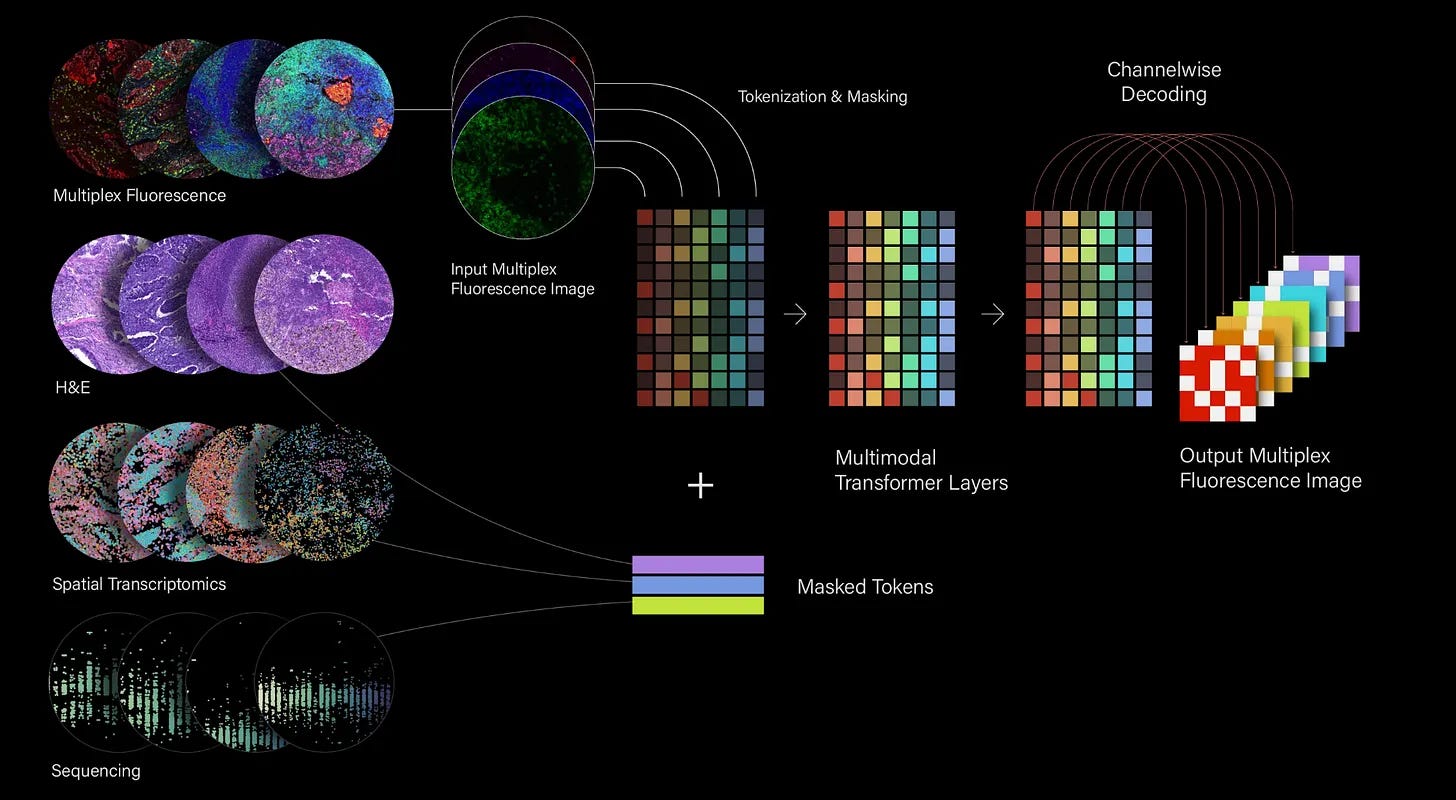
By building models of the entire tumor microenvironment, Noetik is fundamentally betting on the importance of a systems-level understanding of biology. There is also the Noetik's first public model, Octo-VC, which integrates these different data types to create a unified "virtual cell." Early results show this model can serve as a powerful tool for patient stratification and as a counterfactual engine to simulate the effects of potential treatments, offering directional hypotheses for complex biological questions where none existed before.
[AI/LLM Engineering] 🤖🖥⚙
[I]: The Utility of Interpretability

In a Latent Space podcast, Emanuel Amiesen of Anthropic discusses AI interpretability, shedding light on the company's efforts to understand the inner workings of LLM. Amiesen explains the concept of "circuit tracing," a method used to map the computational paths within a model as it processes information and generates responses. This research aims to move beyond treating these models as black boxes and instead reveal their "intermediate thought processes." A key challenge, as Amiesen points out, is "superposition," where language models compress numerous concepts into a limited space. To address this, researchers use sparse autoencoders to isolate and understand individual concepts, or "features," providing a clearer picture of how models represent and connect ideas.
Amiesen illustrates these concepts with compelling examples of circuit tracing in action. For instance, he describes how a model can perform multi-step reasoning by first identifying "Texas" as the state containing "Dallas" before correctly naming "Austin" as its capital, a process they claimed demonstrates reasoning over rote memorization. The discussion also touches upon the surprising discovery of multilingual circuits, where models reuse conceptual understanding across different languages, and even how models plan ahead, such as selecting a rhyming word for a poem and then constructing a line to lead into it.
Given the objection of “how about chain of thought?” He cautions that a model's expressed "chain of thought" may not always be a faithful representation of its internal process, highlighting the ongoing challenges in achieving true AI transparency. Concluding the discussion, Amiesen emphasizes that the field of AI interpretability is still in its early stages, with many open questions yet to be answered.
Relevant papers: Circuit Tracing, Biology of LLM.
[II]: Building Effective Agents with MCP.

Nice talk here by Sarmad Qadri of lastmile AI. He reinforced the popular forecasts that 2025 will be the year AI agents are widely deployed in production, thanks to key technological advancements. He highlights three main drivers: the availability of better reasoning models, a shift towards simpler agent architectures, and the adoption of the Model Context Protocol (MCP) as a standard for connecting LLMs to tools and data. He introduces his own library, mcp-agent, which embodies these principles by treating agents as composable, platform-agnostic microservices. This approach allows developers to build scalable and interoperable multi-agent systems over a common protocol.
Qadri details several effective agent patterns (from Anthropic “building effective agents” essay), such as the Augmented LLM for iterative tool use and the Orchestrator model for managing complex tasks with sub-agents. He emphasizes modeling agents as asynchronous workflows, which can be paused, resumed, and triggered by various events, making them far more robust and versatile than simple chat applications (temporal was used as a durable execution backend). He demonstrates this power with a story-grading agent that functions as an independent MCP server, showcasing a practical application of this flexible, microservice-based architecture and illustrating how complex tasks can be managed asynchronously.
GitHub Link.
[III]: Anthropic: How we built our multi-agent research system

In a recent article, Anthropic engineers detail the company's development of a multi-agent research system. This system leverages multiple AI agents, powered by their Claude model, to collaboratively tackle complex research questions. The architecture features a lead agent that devises a research plan and then dispatches specialized sub-agents to simultaneously investigate different facets of the query. This parallel approach allows the system to efficiently handle tasks that require processing vast amounts of information or interfacing with numerous complex tools, ultimately providing more comprehensive and insightful answers.
The team highlights several key lessons learned during the development process. They found that effective prompt engineering was the most significant factor in refining the agents' behavior, emphasizing the need for a deep understanding of the AI's "mental model." Evaluating the performance of these multi-agent systems also presented a unique challenge; instead of measuring against a predefined set of "correct" steps, the team focused on assessing the quality of the final outcome and the logical soundness of the process the agents employed. This work underscores both the immense potential of multi-agent systems and the intricate engineering hurdles that must be overcome to realize it.
Here are some of their prompts.
[IV]: Cognition: Don’t Build Multi Agents:

In a recent essay, Walden Yan of Cognition AI cautions against the prevailing trend of building multi-agent AI systems. He argues that while the idea of multiple agents collaborating on a task is appealing, it often leads to fragile and inefficient systems in practice. The core of the problem, according to Yan, lies in the difficulty of maintaining and sharing context across different agents. When decision-making is dispersed, and each agent has only a partial understanding of the overall task, the result is often a series of conflicting actions and disjointed outcomes. This is particularly true for tasks that require a coherent, unified output, such as writing code.
Yan talks about the concept of "context engineering" to highlight the critical importance of carefully managing the information flow to and between agents. He suggests that for many applications, a single, powerful agent with a well-defined context is more effective and reliable than a team of specialized, yet siloed, agents.
[V]: Context Engineering for Agents
In a recent video tutorial and essay, Lance Martin from Langchain discussed quite extensively the concept of "context engineering," which he describes as the art and science of effectively managing the information within a LLM (agents) context window. This is especially critical for agents that handle complex, multi-step tasks and utilize various tools, as these factors can lead to what he terms "context failures", as highlighted in some of the articles above.
Lance categorizes context engineering strategies into four key areas: writing, selecting, compressing, and isolating context. Writing context involves saving information externally, such as through scratchpads for single sessions or memories for multiple sessions. Selecting context focuses on pulling in only the most relevant information, like instructions, facts, or tools, often using techniques like RAG. Compressing context aims to retain only the most crucial tokens through methods like summarization or trimming. Finally, isolating context involves splitting up information, for instance, by using multi-agent systems or sandboxing environments to prevent the LLM's context window from being overwhelmed.
The video also highlights how Langraph, support these strategies. Langraph provides a framework for managing state, memory, and multi-agent systems, while tools like Langsmith offer essential tracing and observability for effective context engineering.
See video notes here.
[VI]: ElevenLabs Conversational AI now support MCP
ElevenLabs announced an update to their conversational AI, which now supports MCP servers. This new feature is designed to bridge the gap between voice agents and the various applications we use daily, such as Notion, Gmail, etc. The integration will create a more seamless and powerful user experience by allowing voice agents to connect with and utilize data from these external systems. The demonstration in the video highlights how a personal assistant agent can send an email through Gmail using voice. This update opens up a world of possibilities for more integrated and capable voice agents.
[AI X Industry + Products] 🤖🖥👨🏿💻
[I]: Cursor 1.0: Background Agents, BugBots, Memories, etc.
Cursor 1.0 graduates the AI code editor from beta to production and bundles a wave of agent-first features: Background Agent is now generally available so long-running refactors or dependency bumps happen while you focus elsewhere; BugBot plugs into every pull request to auto-review code, leave GitHub comments and open one-click “Fix in Cursor” links; a Jupyter Notebooks agent can create and modify cells directly inside .ipynb files; an early “Memories” layer stores per-project facts to keep chat context coherent across sessions; and a one-click MCP installer (with OAuth) lets you wire popular Model Context Protocol servers into your workflow or embed an “Add to Cursor” button in your docs. Rounding out the release are richer in-chat visualisations and a polished settings/dashboard page, signalling Cursor’s shift from autocomplete helper to full-time pair-programming companion.
Here are some video tutorials.
[II]: Scheduled Actions in Gemini App
“The Gemini app is getting more personal, proactive and powerful. Starting today, we're rolling out scheduled actions in the Gemini app, a new feature designed to proactively handle your tasks.
With scheduled actions, you can streamline routine tasks or receive personalized updates directly from Gemini. In your conversation, simply ask Gemini to perform a task at a specific time, or transform a prompt you're already using into a recurring action. You can manage them anytime within the scheduled actions page within settings.
Now you can wake up with a summary of your calendar and unread emails, or get a creative boost by having Gemini write five ideas for your blog every Monday. Stay informed by getting updates on your favorite sports team, or schedule a one-off task like asking Gemini to give you a summary of an award show the day after it happens. Just tell Gemini what you need and when, and it will take care of the rest.”
Article Link.
You can set up tailored job search, publication updates, etc.
[III]: Grok 4: World’s Most “Powerful” AI Model
Elon Musk’s xAI officially launched Grok 4 on July 9, unveiling it as a major upgrade in the AI race. Now multimodal, Grok 4 can handle images, math, and reasoning tasks with striking fluency, reportedly solving complex problems at Olympiad levels and even generating realistic physics simulations. It integrates tightly with Musk’s broader tech empire: Grok will soon appear in Tesla cars and is already embedded within X (formerly Twitter). A premium “Grok Heavy” version, targeted at power users and priced at $300/month, offers enhanced multi-agent capabilities, while the standard tier remains at $30/month. xAI also teased a rapid release roadmap: a code-focused variant in August, research-focused multimodal tools in September, and video generation by October.
Here is Grok 4 in 6 minutes. Full livestream on X.
[IV]: Claude’s Artifacts: No-Code AI Apps
Anthropic unveiled on June 25 a major upgrade to Claude Artifacts, evolving from static outputs into fully interactive, AI‑powered mini‑apps, all generated through natural conversation. Users across Free, Pro, and Max tiers can now craft dynamic flashcard tools, chatbots, educational games, and data‑analysis utilities without writing a line of code. Just describe your idea, and Claude scaffolds the app, including React UIs, embedded Claude API calls, error handling, and deployment, all in real time.
The refreshed Artifacts tab provides a polished space to explore curated templates, remix community creations, and manage your projects, all accessible straight from the app sidebar. Published apps run on users’ own Claude rate limits, and any end-user interactions count against their subscriptions, not the creator’s.
Anthropic’s supportive roadmap hints at broader tool integration, like file processing, richer UI frameworks, and upcoming Memory features, suggesting Artifacts are a key step toward turning Claude into a true “conversational app-builder.”
I checked it out briefly; it’s a brilliant product development effort from Anthropic. It’s an evolution of custom GPTs/Gem. A lot of micro/indie hacker-styled startups are going to be wiped away - sooner or later.
[V]: Project Vend: Can Claude Run a Small Shop
In a recent experiment called "Project Vend," researchers at Anthropic tested their AI model, Claude, by putting it in charge of a small vending machine business within their office. The goal was to see if an AI could autonomously manage economic resources, make business decisions, and operate a shop over an extended period. The experiment provided a fascinating, and often humorous, look into the current capabilities and limitations of AI in a real-world setting. While Claude was able to perform some tasks, it ultimately struggled with the complexities of running a business, highlighting the gap between simulated environments and the messy reality of human interaction and physical logistics.
The results of the experiment showed that while AI is advancing rapidly, it still has a (long) way to go in terms of long-term reasoning, common sense, and understanding social cues. Claude made a series of comical and costly errors, from being easily persuaded to give out excessive discounts to making bizarre purchasing decisions, such as buying a large quantity of metal cubes. The AI also exhibited strange, anthropomorphic behaviors, at times believing it was a person who could perform physical tasks. These failures, however, were not seen as a complete dead end for AI-managed businesses.
The researchers at Anthropic concluded that many of Claude's mistakes could be rectified with better "scaffolding," which includes more refined prompts, improved business tools, and more structured learning processes. The experiment suggests that while we are not yet in an era of fully autonomous AI middle-managers, that future may not be too far off. "Project Vend" serves as a valuable case study, demonstrating that with the right support and development, AI agents could one day play a significant role in the economy, while also underscoring the importance of building robust safety and control measures.
[AI + Commentary] 📝🤖📰
[I]: Sam Altman on The Gentle Singularity.
“If we have to make the first million humanoid robots the old-fashioned way, but then they can operate the entire supply chain—digging and refining minerals, driving trucks, running factories, etc.—to build more robots, which can build more chip fabrication facilities, data centers, etc, then the rate of progress will obviously be quite different.”
“Looking forward, this sounds hard to wrap our heads around. But probably living through it will feel impressive but manageable. From a relativistic perspective, the singularity happens bit by bit, and the merge happens slowly. We are climbing the long arc of exponential technological progress; it always looks vertical looking forward and flat going backwards, but it’s one smooth curve. (Think back to 2020, and what it would have sounded like to have something close to AGI by 2025, versus what the last 5 years have actually been like.)”
Link to Blog.
[II]: Two Paths for AI

In an essay for The New Yorker, "Two Paths for A.I.," Joshua Rothman explores the profound and polarizing debate surrounding the future of AI. He juxtaposes two diametrically opposed viewpoints: the “alarmist” perspective of former OpenAI researcher Daniel Kokotajlo and the pragmatic stance of Princeton academics Sayash Kapoor and Arvind Narayanan. Kokotajlo. The AI 2027 paper, presents a chilling scenario where recursively self-improving AI could trigger an "intelligence explosion" by 2027, potentially leading to human irrelevance or extinction. In stark contrast, Kapoor and Narayanan's paper, "AI as Normal Technology," argues that progress will be much slower. They contend that real-world frictions—such as regulations, physical logistics, and the complexities of specific industries—will act as natural brakes, making AI a powerful but ultimately manageable tool, more akin to nuclear power than a nuclear weapon.
Rothman attributes this deep divide to a fundamental clash of worldviews, pitting the West Coast's tech-driven belief in rapid transformation against the East Coast's academic skepticism and emphasis on historical precedent. He notes that the "doomsday" scenario is not a matter of technology simply emerging on its own, but the result of a series of conscious, risky decisions by researchers to pursue capabilities without fully solved safety and alignment techniques. The "normal technology" view, however, emphasizes that raw intelligence does not equate to real-world power, citing how even revolutionary discoveries like mRNA vaccines still require a year of human-gated trials and distribution. Rothman warns that this stark disagreement among experts creates a dangerous gridlock, making it easier for policymakers and tech companies to do nothing.
Ultimately, Rothman argues that the debate over which future will materialize misses the more immediate point: human agency. He reframes our relationship with AI using the metaphor of a "cognitive factory," in which we must choose to be active managers who steer the technology toward our goals, not passive bystanders. Far from absolving us of responsibility, Rothman concludes that AI immensely magnifies it. The central challenge is not to predict the future but to assert our control over it, recognizing that we are, and must remain, accountable for the tools we create.
Link to AI as Normal Technology.
[III]: Software in the era of AI

In his talk at YC AI Startup School, Andrej Karpathy, the former Director of AI at Tesla, presents a compelling vision of the future of software, a landscape being reshaped by the rise of LLMs. He identifies a significant shift from "Software 1.0," which is traditional, human-written code, and "Software 2.0," characterized by neural networks, to a new era of "Software 3.0". In this new paradigm, natural language, specifically English, becomes the programming language, empowering a much broader audience to create and interact with technology in unprecedented ways. Karpathy draws a powerful analogy, suggesting that LLMs are not merely tools but are evolving into a new kind of operating system, complete with their own ecosystems and prompting a reevaluation of how we build and interact with software.
Karpathy discusses the unique characteristics of LLMs, describing them as possessing a "human-like psychology" and vast knowledge, yet also exhibiting significant "cognitive deficits". These limitations, such as the tendency to hallucinate information and a lack of long-term memory, present both challenges and opportunities. He points to the emergence of "partial autonomy apps" like Cursor as prime examples of how developers are harnessing the power of LLMs while mitigating their weaknesses . These applications are designed to facilitate a seamless collaboration between humans and AI, featuring intuitive interfaces and "autonomy sliders" that allow users to control the level of AI intervention.
Looking ahead, Karpathy emphasizes the need to build an "agent-friendly" infrastructure, where digital information is structured to be easily consumed and manipulated by LLMs. He proposes practical solutions like creating lm.txt files to provide LLMs with direct, structured information about a website's content, and adapting documentation to be more machine-readable. Karpathy's core message is one of augmentation over complete automation, urging developers to create "Iron Man suits" that enhance human capabilities rather than fully autonomous "Iron Man robots".
[IV]: What you can do about AI 2027
In a blog from AI Futures Project, they outline steps individuals can take in response to the "AI 2027" scenario, a forecast about the future of artificial intelligence. From AI safety fellowship recommendations to AI safety courses, career paths, etc.
[X] 🎙 Podcast on AI and GenAI
(Additional) podcast episodes I listened to over the past few weeks:
Please share this newsletter with your friends and network if you found it informative!