


My Other Publications:
Around the Web Issue 34: The Dangers of the Hackneyed Dangers of Social Media 🤳
Video Essays: Rainforest vs. Boardrooms, Humanity’s Persistent Bug, and From Rebels to Rulebooks.
In this newsletter:
[LLM/AI for Science et al] 🤖 🦠 🧬
[I]: 🧬Genomics and GenAI
In this essay, I explain/review how advanced AI, particularly transformer-based language models originally designed for human language, are being repurposed to decode the complex language of life—DNA, RNA, and proteins (primarily DNA in this essay). The essay details how these models are used to predict protein functions, identify co-regulated gene clusters, and even design synthetic genes. Highlighting studies such as the one by Hwang et al., where millions of metagenomic scaffolds can generate contextual protein embeddings that reveal critical functional and regulatory connections across species. Additionally, the Evo model, with its 7-billion parameter architecture, is showcased for its ability to predict gene functions and generate complex biological structures, marking significant strides in genome engineering and evolutionary biology. I also reviewed a paper on the power of species-aware DNA language models in capturing regulatory elements across diverse organisms, providing fresh insights into evolutionary adaptations and gene regulation. You can read the essay here:

In a similar vein, the next entry is a very cool paper that was recently published.
[II]: 🦠A Transcription Foundation Model

In simpler terms, Xi Fu and co-workers introduce a new foundational model called GET that can predict how genes are turned on or off across many different human cell types—even ones it hasn't seen before. Instead of relying on complex and often limited models, GET uses information about which parts of the DNA are accessible along with the DNA sequence itself to accurately forecast gene expression. This means it can map out how various regulatory regions and proteins interact to control gene activity.
Moreover, GET doesn't just predict gene expression—it also uncovers previously missed gene regulatory elements and specific interactions between transcription factors. For instance, it found new regulatory regions in fetal blood cells and revealed a particular protein interaction in B cells that may explain a risk factor for leukemia. Overall, GET is a more general and accurate tool that offers a detailed catalog of gene regulation across different cell types, potentially advancing our understanding of how genes drive both normal functions and diseases.
If you want more than this short abstract, and don’t want to read the full paper, this 6 minutes-article is probably what you need. Cool work.
[III]: 🧑🎓️Ai2 ScholarQA for Literature Review
AI2, a non-profit AI institute out of Seattle, released a new experimental tool that leverages a RAG methodology to streamline literature reviews by synthesizing evidence from multiple documents. At its core, the system uses Vespa cluster index containing about 8 million open-access academic papers—updated weekly—and employs a combination of BM25 and dense embeddings to retrieve relevant snippets. Once the top passages are identified, a multi-step prompting workflow with Claude Sonnet 3.5 model drives the process: first extracting key quotes to reduce context overload, then outlining and clustering these quotes into structured sections (either as detailed paragraphs or bulleted lists), and finally generating a comprehensive report complete with TLDR summaries and precise citations.
Complementing this process, Ai2 ScholarQA introduces an innovative two-step framework for generating literature comparison tables, a critical tool for researchers. In this approach, schema generation and value generation are decoupled: the model first creates clear, defined column schemas—using paper titles, abstracts, and the initial user query to encapsulate user intent—and then populates these schemas by prompting the full text of each paper to produce cell values with supporting snippets. This method not only improves specificity and quality while reducing hallucinations but also has been benchmarked using the ArXiVDigestable dataset, underscoring its potential to enhance the accuracy and depth of comparative analyses in scientific research.
I am planning/thinking on working on LLM fine tuning for predictive chemistry next for my research, so I used ScholarQA to query: “LLM fine tuning techniques for predictive chemistry.” The response to the query looks solid to me.
Outline:

Technical implementation details opened up:

Table generated inside technical implementations

You can read the entire response here.
ScholarQA gives me the vibe of Gemini Deep Research, but a lingering question I had was: How does this compare with PaperQA? I made a perplexity page about it, you can read it here.
[AI/LLM Engineering] 🤖🖥⚙
[I]: 🕵Ambient Agents
In this article, LangChain introduces the concept of “ambient agents” as an alternative to the typical chatbot-driven user interface. These agents don’t rely solely on users to initiate tasks or manage workflows, but instead listen to an event stream and act autonomously when needed. By operating on multiple events at once and only demanding user input when crucial, ambient agents reduce the overhead of constant chat interactions and help users scale their attention more effectively.
A key pillar of ambient agents is the human-in-the-loop mechanism. Ambient agents pause to notify you of significant events, ask for clarification when they lack critical information, or request a review before performing consequential actions—such as sending an email. This structured interplay between automation and human oversight builds trust by preventing mistakes, fostering better alignment between user preferences and agent behavior, and mimicking the natural flow of human collaboration.
Finally, LangChain showcases the value of its LangGraph platform by highlighting how it seamlessly supports ambient agent workflows. With built-in persistence, long-term memory, and integrated scheduling, LangGraph makes it easier to manage, track, and refine tasks in one centralized system. LangChain presented an email assistant example that demonstrates these concepts in action, serving both as a live product users can try and an open-source reference implementation for building their own ambient agent solutions. It appears the live product, Agent Inbox, has now been halted. Nevertheless, here is an instruction on how to “hire” and “communicate” with a LangChain's hosted AI Email Assistant. Also, see the YouTube walkthrough.
For the open source implementation, here is the code, and here is the walkthrough.
[II]: 🕸 Defining Agents
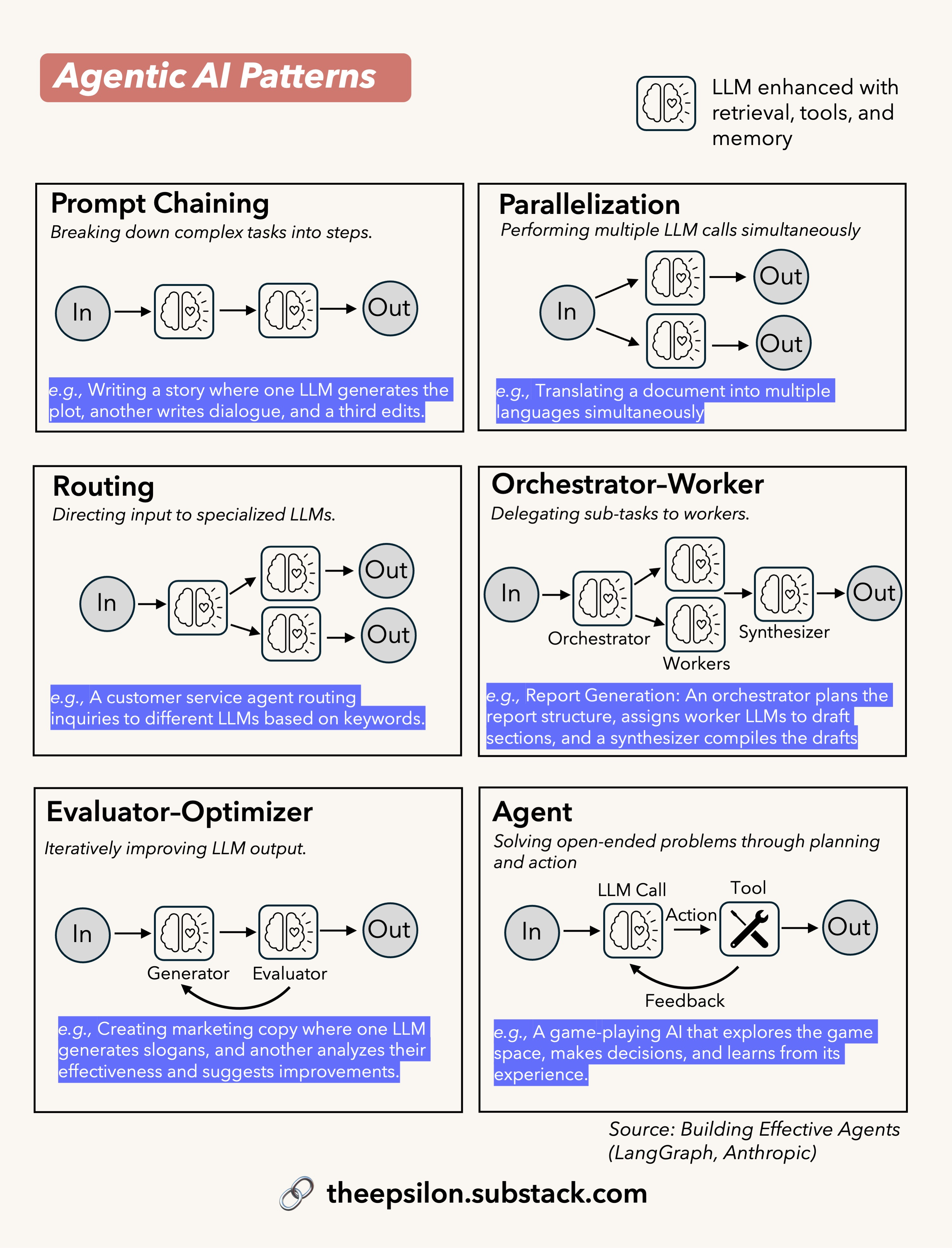
In this essay I wrote Iast week, I explore how we classify and build AI agents by dissecting two key axes that guide my thinking: the framework axis and the emerging pattern axis. For the framework axis, I presented a CrewAI (high level) vs LangGraph (Low level) distinction. I also reflected on a previous commentary I made on Anthropic’s "Building Effective Agents" essay—I argue that there exists a misalignment in how different communities define and build these systems. I also break down the implementation of five agentic patterns: prompt chaining, routing, parallelization, orchestrator-workers, and evaluator-optimizer as argued by Anthropic.

[III]: 🤳Open Source Social Media Agent.
Folks at LangChain recently introduced a new open-source social media agent, in the spirit of the ambient agent discussed above, that can automate the process of scheduling posts on Twitter and LinkedIn. This agent takes a URL, scrapes the content, generates a marketing report, finds relevant images, and creates social media posts. After generating the posts, it pauses for user feedback before scheduling them. Their tutorial demonstrates how to use the agent, set it up locally, and provides a detailed explanation of how the agent works. The agent can be customized to fit specific needs and preferences, making it a versatile tool for managing social media content. See code.
[IV]: 🔍Building Research Assistant with DeepSeek-R1 and o3 mini.
In this video, Lance Martin from LangChain first introduces DeepSeek-R1 (more on this below) and then he uses the model to actually build a pretty neat research assistant. Perhaps as a response to the release of DeepSeek-R1 (I am not sure what the sequence of events are, things are moving pretty fast) OpenAI, actually releases a new reasoning model o3-mini on chatGPT. Though they have previewed o3 in December, and I shared it on this newsletter. o3-mini is a more affordable and faster version of its predecessor, o1. Here is another tutorial on how to build a research assistant with o3-mini.
In the videos, an important distinction was made between a chat model and a reasoning model, and I think this is actually quite warranted because a lot of users might be confused when to actually use these different kinds of models.

Here are the video notes for local DeepSeek-R1 and o3-mini.
[V]: 🦇Sonar Pro API
I have always been on the lookout for a nice API for grounding LLM's output with adequate citations. So I'm really glad that Perplexity actually has this new API out. They wrote about it here:
It's never been a better time to build with AI. But as AI tools become more pervasive, accuracy is paramount. While most generative AI features today have answers informed only by training data, this limits their capabilities. To optimize for factuality and authority, APIs require a real-time connection to the Internet, with answers informed by trusted sources. With Perplexity's Sonar and Sonar Pro API (the latter generally available to all developers starting today), you can build your own generative search capabilities powered with unparalleled real-time, web-wide research and the Perplexity features you've come to expect, like citations.
I also wasn't quite sure, when I first heard about Sonar about how it contrasts with APIs like Tavily’s API, but it turns out to be a quite different and much more robust solution. Here is also a link to a Perplexity page that I have curated if you want to read about it.
[AI X Industry + Products] 🤖🖥👨🏿💻
[I]: 🐳DeepSeek R1
One of the finest materials I found online about DeepSeek R1 - when it was first released - was from Sam Witteveen. In his "DeepSeekR1 - Full Breakdown" video, he explores the newly released model, highlighting its impressive capabilities and the innovative techniques behind its development. He begins by showcasing the model's performance on various benchmarks, which is pretty much at par with OpenAI's o1 model. (I tried it on my internal ‘test dataset’, and it is very comparable to o1). And considering that the Deep Seek R1 is open source and significantly cheaper, that’s simply bonkers. Witteveen emphasizes the significance of the model's multi-stage training process, which leverages reinforcement learning and a unique prompt template to encourage the model to generate chains of thought, ultimately leading to superior results. Here is the paper.
(This first part of this video from LangChain also explains the training of deep seek beautifully)
Witteveen also demonstrates how to access and utilize the distilled versions of the model, making it possible to experiment with these powerful models even on limited hardware. Here is the Colab notebook. The DeepSeek R1 model has difficulty with adopting personas, creative writing tasks, and tool use. It also struggles with generating structured outputs like JSON. If you have not you can try out the actual full model here. Its reasoning is as good as these things get these days. Powerful stuff. Full Announcement on 𝕏.
Perplexity’s CEO, Aravind’s take: “It's kinda wild to see reasoning get commoditized this fast. We should fully expect an o3 level model that's open-sourced by the end of the year, probably even mid-year.”
Marc Andreseen: “Deepseek R1 is one of the most amazing and impressive breakthroughs I’ve ever seen — and as open source, a profound gift to the world.”
Here is a nice article on DeepSeek R1 vs OpenAI o1 from folks at PromptLayer.
Deep Seek R1 is also available for reasoning in Perplexity Pro – an excellent product I have to say.
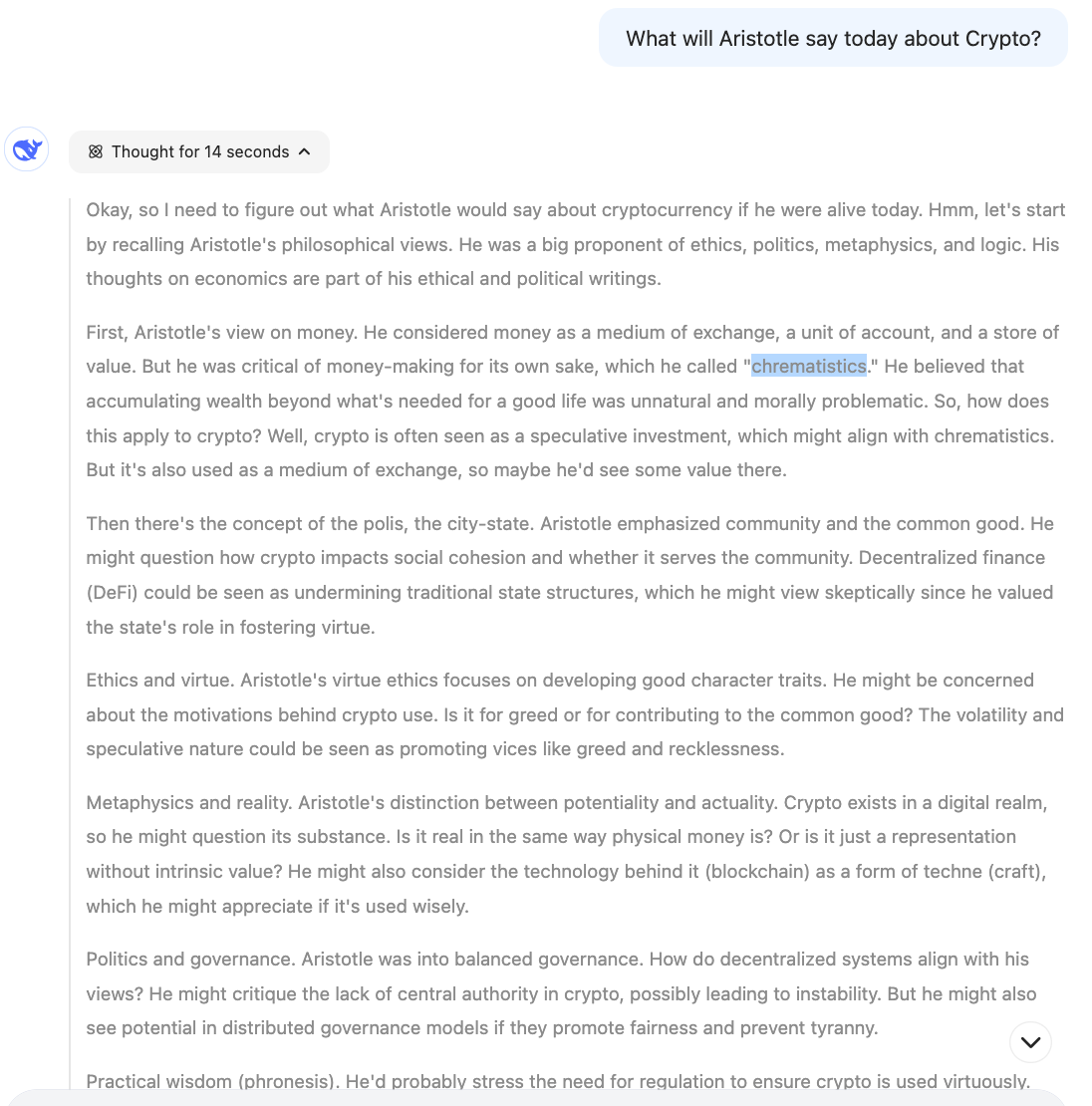
In the meantime R1 on Aristotle on Crypto according:
[II]: 👤RealAvatar.ai
A startup that allows you to talk to the avatar of today's greatest minds, starting with Andrew Ng. I tried it, it works great. I suppose it's a good product to figure out what somebody you think highly of thinks about a subject, or how they would address a problem. I tried it out with Ng, and it worked just fine. My guess is that this is the worst it would ever be.
[III]: 𝕏 Grok
It is no longer news that 𝕏 has released Grok as a standalone AI app. And I really like the fact that it does actually ground some of its answers in 𝕏 posts. One of the reasons why I actually go on Twitter, sorry 𝕏, is basically to read and learn about current AI releases. So I suppose Grok will be really helpful in this regard, consolidate my ‘fishing expedition’, and save me a lot of time from being pulled into the almighty rabbit hole of 𝕏.
Grok leverages the 𝕏 platform to understand what's happening in the world in real time. We recently launched two additional features to enhance this experience even further: web search and citations. Now Grok draws upon posts from 𝕏 and webpages from the broader internet to provide timely and accurate answers to your queries. We also added citations, so you can easily dive deeper into a source to learn more or verify the information provided by Grok.
You can try the web version here.
[IV]: 📝ChatGPT ‘Tasks’, Canvas, and Preview
OpenAI recently launched ChatGPT Tasks, a pretty neat feature.
OpenAI is launching a new beta feature in ChatGPT called Tasks that lets users schedule future actions and reminders.
The feature, which is rolling out to Plus, Team, and Pro subscribers starting today, is an attempt to make the chatbot into something closer to a traditional digital assistant — think Google Assistant or Siri but with ChatGPT’s more advanced language capabilities.
Tasks works by letting users tell ChatGPT what they need and when they need it done. Want a daily weather report at 7AM? A reminder about your passport expiration? Or maybe just a knock-knock joke to tell your kids before bedtime? ChatGPT can now handle all of that through scheduled one-time or recurring tasks.
Many interesting use cases out there, like daily stock market analysis, writing stories with Canvas on a regular basis and sending it to your inbox, prompt you to learn a new language. You can even see more here.
I am currently learning some web development skills, and I have one recurring task to help in that regard. I really like the feature.
ChatGPT Canvas + Preview.
One of the reasons I switched from ChatGPT to Anthropic’s Claude, briefly, last year was because of the Claude 3.5 Artifacts (Analogous to OpenAI's Canvas.). But then OpenAI had better models or at least equally good models, and I switched back to ChatGPT. But now ChatGPT has actually introduced canvas (I haven't played with it as much, though, too many things to try!). ChatGPT Canvas is for all ChatGPT users. Read about how to use it here.
[V]: 🎢OpenAI Operator / Browser Use
OpenAI introduces Operator, an AI system that uses a web browser to complete tasks independently. Operator is an early research preview with potential for growth, but it can already do things like book reservations, order groceries, and purchase tickets. Operator is based on a model which is trained to use and control a computer in the same way that humans can. Operator is able to do this by looking at the screen and using a mouse and keyboard to control it. This allows Operator to complete a wide range of tasks that were previously inaccessible to AI agents. Operator is still under development, but it has the potential to revolutionize the way we interact with computers. Blog introduction.
Very interesting use cases: find a new way to treat polycystic ovary syndrome, using operator to do sales, Operator X Replit agent, and Operator to build web apps in Bubble.
There is also an open source alternative to OpenAI Operator called Browser Use. Here is a demo.
I haven’t tried any of these, but I intend to use Browser Use.
[VI]: 🧑💻️OpenAI Deep Research
OpenAI introduces Deep Research, a new agentic capability within ChatGPT, designed to streamline complex research tasks. Deep Research empowers ChatGPT to independently conduct multi-step research across the internet, tackling projects that would typically require significant human effort. This new feature is intended to drastically reduce the time investment needed for in-depth investigations, potentially condensing hours of work into mere minutes.
The key to Deep Research's capabilities lies in a specialized version of OpenAI's forthcoming o3 model. Optimized for web browsing and data analysis, this model allows ChatGPT to not only search the internet but also interpret and analyze the vast quantities of text, images, and PDFs it encounters. This analytical capacity enables the agent to adapt its research strategy on the fly, pivoting as needed in response to new information, mimicking the dynamic process of human research. Essentially, Deep Research equips ChatGPT with the ability to autonomously navigate the complexities of online information.
With things like Deep research, I am not quite sure how a sizable part of academia will survive. This is not the first time I am covering a Deep Research feature on this newsletter, and in my last newsletter, I covered Gemini Deep Research and I remarked:

I have played with (gemini) Deep Research and it is not nothing. Based on my internal use cases it beats Perplexity Pro, and Perplexity Pro is already too good.
Unfortunately for me, as a postdoc, I can’t afford a $200/month subscription. But based on what I've seen online, and given the fact that it's using an o3 model under the hood, I'm almost certainly sure it's going to be better than the current Gemini deep research, which is powered by Gemini 1.5 Pro. In the meantime I suppose I have to wait for Google’s Deep Research powered by Gemini 2.0.
See OpenAI Deep Research Demo here. Very interesting examples and takes: deepseek research overview, Sam Altman’s take: " [Deep Research] is a system that can do a single-digit percentage of all economically valuable tasks in the world", McKay Wrigley take, and there is more here.
[VII]: 📱Replit Agent on Mobile
I have written about Replit agents and assistants in my last newsletter. However, it appears that they just released agents on the mobile app. Essentially having a software developer in your pocket. Here is the demo.
I tried the free tire to build a simple interactive app to learn web app, and it worked just fine. Here is my previous post on Replit.
[AI + Commentary] 📝🤖📰
[I]: 📞 a16z on Voice Agents
Comprehensive presentation on AI voice agent market landscape from a16z:
Their thesis:
Voice is one of the most powerful unlocks for AI application companies. It is the most frequent (and information dense) form of communication, made "programmable" for the first time due to AI.
For enterprises, AI directly replaces human labor with technology. It's cheaper, faster, more reliable — and often even outperforms humans. Voice agents allow businesses to be available to their customers 24/7 to answer questions, schedule appointments, or complete purchases. Customer availability and business availability no longer have to match 1:1 (ever tried to call an East Coast bank after 3 p.m. PT?). With voice agents, every business can always be online.
For consumers, we believe voice will be the first — and perhaps the primary — way people interact with AI. This interaction could take the form of an always-available companion or coach, or by democratizing services, such as language learning, that were previously inaccessible.
We are just now transitioning from the infrastructure to application layer of AI voice. As models improve, voice will become the wedge, not the product. We are excited about startups using a voice wedge to unlock a broader platform.
[II]: 💻AI’s Impact on Content and Code
Here, Rex Woodbury argues that while the internet initially shattered mainstream culture by breaking open distribution channels—fragmenting audiences and dissolving traditional gatekeepers—AI is set to take this a step further by breaking open production itself. Woodbury illustrates how cultural touchstones have dispersed, evidenced by the decline in shared media experiences (from one in five Americans sharing a favorite athlete to one in twenty) and the explosion of online content exemplified by platforms like YouTube. He draws parallels with the fragmentation of software, noting that just as traditional media was unbundled, so too will software creation be radically transformed by AI tools that lower production costs and democratize creative output (Replit Agent above is a case in point)
Woodbury highlights emerging startups as prime examples of this shift: Sekai, which uses AI and blockchain to reinvent storytelling and fan fiction, and Lovable, a tool that enables rapid, AI-driven software development. Both platforms underscore his thesis that as AI makes content and code easier and cheaper to produce, the resulting explosion in creative output will extend the long tail of cultural and technological niches. Ultimately, he contends that the real value and competitive moat will lie in the companies that build robust tools and networks to harness this proliferation, setting the stage for a renaissance in both content and software creation.
[III]: 📱How AI will Invigorate Consumer Tech
Here again, Rex Woodbury argues that consumer tech is on the brink of a renaissance, driven by AI ability to disrupt and reinvent longstanding market categories. Despite recent declines in venture capital interest—evidenced by a drop in seed funding for consumer startups—Woodbury reminds us of the outsized successes of companies like Uber, Airbnb, and Roblox, underscoring the enduring potential of consumer innovation. He contends that AI is set to reinvigorate consumer tech much like mobile and cloud did in their early days, forecasting the emergence of multiple billion-dollar companies by streamlining production and enhancing user engagement.
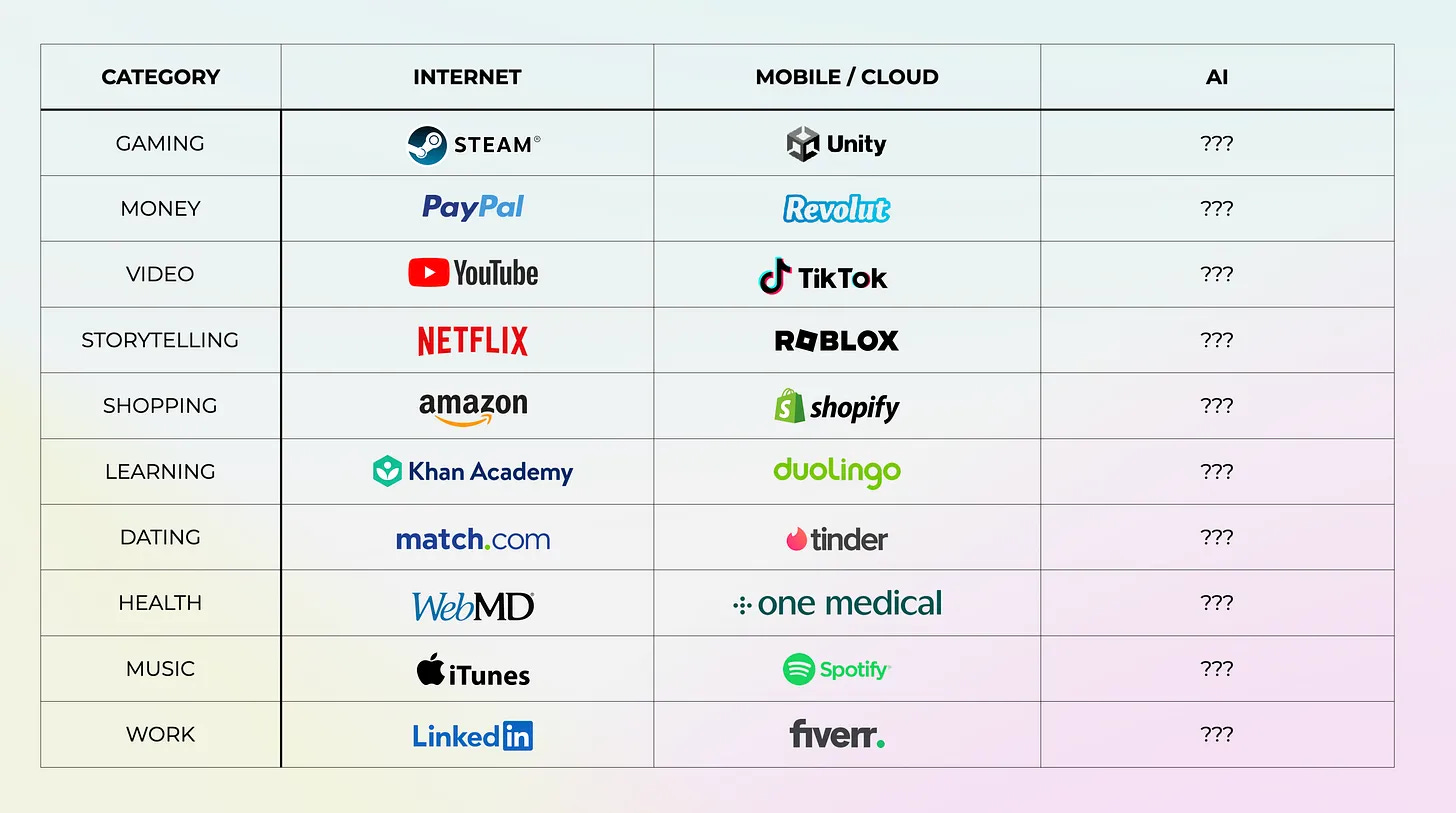
Woodbury outlines ten key sectors ripe for transformation—including gaming, money, video, storytelling, shopping, learning, dating, health, music, and work—each poised to benefit from AI-driven advances. He highlights how AI will simplify game creation, personalize financial management, and revolutionize media production, while also enabling new forms of interactive storytelling and dating experiences. With AI lowering barriers to innovation and offering unprecedented personalization.
[IV]: 🇺🇸United States Copyright Office on AI and Copyright
The U.S. Copyright Office released Part 2 of its Artificial Intelligence and Copyright Report on January 29, 2025, focusing on the copyrightability of AI-generated content. I couldn’t get the time to read so i just it to fed Gemini 2.o Flash and asked it what the main takes were:
- AI-generated content is not eligible for copyright protection.
- Questions of copyrightability and AI can be resolved under existing law, without the need for legislative change.
- The use of AI tools to assist rather than stand in for human creativity does not affect the availability of copyright protection for the output.
- Copyright protects the original expression in a work created by a human author, even if the work also includes AI-generated material.
- Copyright does not extend to purely AI-generated material, or material where there is insufficient human control over the expressive elements.
- Whether human contributions to AI-generated outputs are sufficient to constitute authorship must be analyzed on a case-by-case basis.
- Based on the functioning of current generally available technology, prompts do not alone provide sufficient control.
- Human authors are entitled to copyright in their works of authorship that are perceptible in AI-generated outputs, as well as the creative selection, coordination, or arrangement of material in the outputs, or creative modifications of the outputs.
- The case has not been made for additional copyright or sui generis protection for AI-generated content.
[V]: 🔍What will AI do to (p)research?
Joshua Gans explores how AI is revolutionizing the research process by drastically reducing the time and effort required to produce academic work. In his own experiment, he used Open AI’s o1 Pro to generate and refine a paper—from conceptualizing a model on time travel economics to addressing peer review concerns—demonstrating that what used to take weeks or months can now be accomplished in mere hours. This example underscores his thesis that AI can transform research into a "research-on-demand" model, challenging the traditional notion of doing work now for potential future use.
Gans further argues that if knowledge can be generated as needed (that is, on demand), the current “presearch” model—with its extensive, often redundant work that may never be used—could collapse. In this emerging paradigm, the conventional research process becomes less valuable than simply generating answers when questions arise, effectively blurring the lines between research and search. While this shift promises greater efficiency and productivity, it also raises profound questions about the future role and value of traditional academic inquiry. And talking about the idea of research-on-demand. My favorite product in this domain is Perplexity Pages. It's really powerful. If you have clicked on a few of my links, you would have probably seen Perplexity pages being used.
[VI]: 🤯Jim Fan on the Future of AI (Re: Deep Seek)
Whether you like it or not, the future of AI will not be canned genies controlled by a "safety panel". The future of AI is democratization. Every internet rando will run not just o1, but o8, o9 on their toaster laptop. It's the tide of history that we should surf on, not swim against. Might as well start preparing now. DeepSeek just topped Chatbot Arena, my go-to vibe checker in the wild, and two other independent benchmarks that couldn't be hacked in advance (Artificial-Analysis, HLE). Last year, there were serious discussions about limiting OSS models by some compute threshold. Turns out it was nothing but our Silicon Valley hubris. It's a humbling wake-up call to us all that open science has no boundary. We need to embrace it, one way or another. Many tech folks are panicking about how much DeepSeek is able to show with so little compute budget. I see it differently - with a huge smile on my face. Why are we not happy to see *improvements* in the scaling law? DeepSeek is unequivocal proof that one can produce unit intelligence gain at 10x less cost, which means we shall get 10x more powerful AI with the compute we have today and are building tomorrow. Simple math! The AI timeline just got compressed. Here's my 2025 New Year resolution for the community: No more AGI/ASI urban myth spreading. No more fearmongering. Put our heads down and grind on code. Open source, as much as you can. Acceleration is the only way forward.
[X] 🎙 Podcast on AI and GenAI
(Additional) podcast episodes I listened to over the past few weeks
Please share this newsletter with your friends and network if you found it informative!