


ε Pulse: Issue #23
Vibe Coding ✌️, OpenAI Agents SDK🕵, and The Political Economy of Manus AI🇨🇳.


My Other Publications:
Around the Web Issue 35: Everything is a Game 🎲
Video Essays: When AI Writes Who Thinks.
In this newsletter:

[LLM/AI for Science et al] 🤖 🦠 🧬
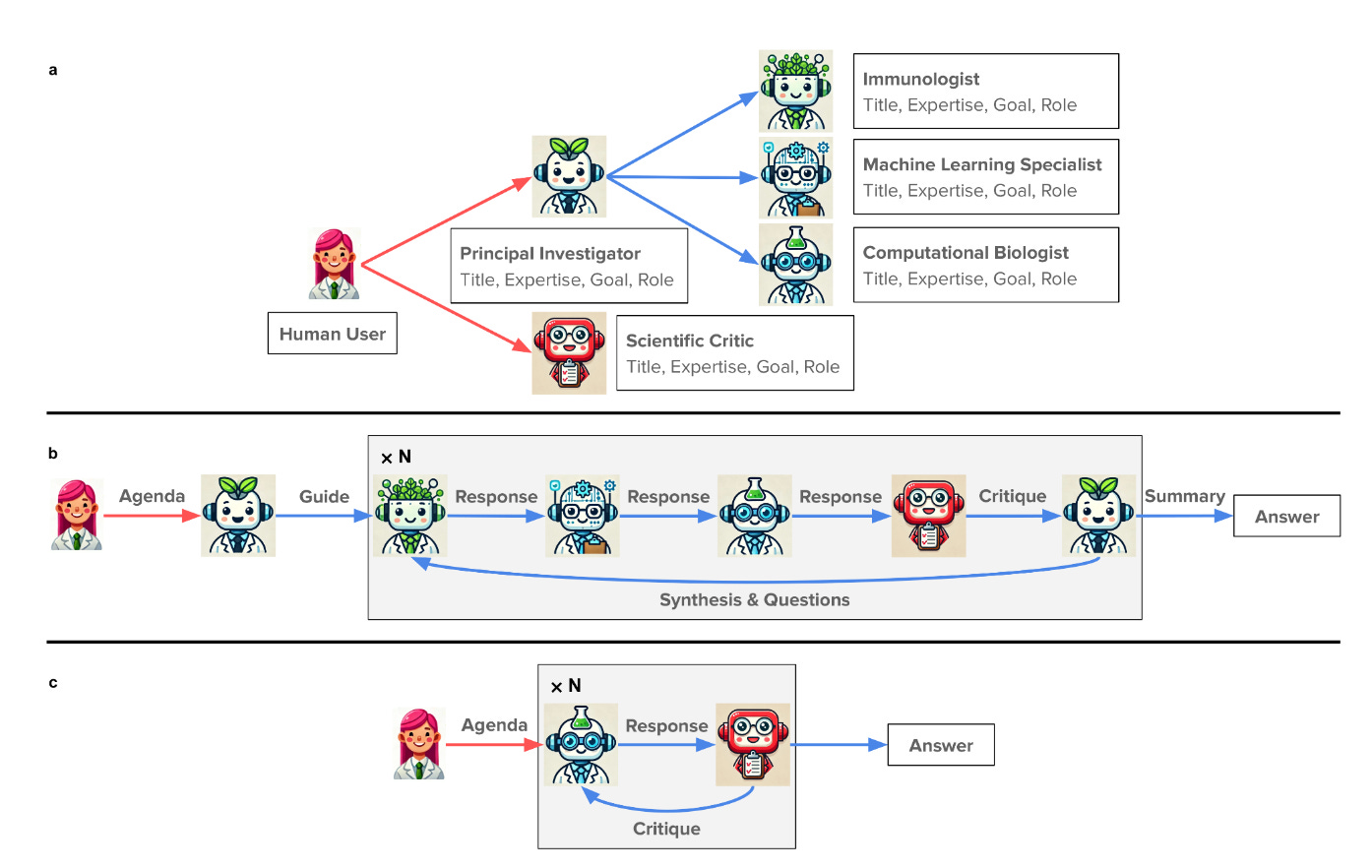
[I]:🥼Virtual Lab: AI Agents Design SARS-CoV-2 Nanobodies
This is one of the papers that has been on my ‘shelf’ for a couple months now, so I am glad to be finally getting to it.
Summary: The paper "The Virtual Lab: AI Agents Design New SARS-CoV-2 Nanobodies with Experimental Validation" introduces a AI-human collaborative research framework called the Virtual Lab, which employs LLM to conduct interdisciplinary scientific research. The Virtual Lab features an AI-driven principal investigator (PI) coordinating a team of AI scientist agents with different expertise (such as a computational biologist, immunologist, and machine learning specialist), working alongside a human researcher. For each agent, the underlying LLM is GPT-4o supplemented with domain-specific tools such as Alphafold. Demonstrating its potential, the Virtual Lab designed 92 nanobody candidates targeting new SARS-CoV-2 variants, two of which showed promising experimental binding results.

//A few other points, I think a platform app for this will be really powerful, and it shouldn’t be hard to build in principle, all you need is a careful curation of tools, and prompts. Clearly, the future lab would be collaboration (and hence lab meetings) with, and between domain expert AI agents. Conversation ‘observability’ tools will be germane, e.g. in the paper they stated

I got confused for a little bit by the use of the word agents, but what they call individual agents are really what I understand to be nodes (augmented LLM) in an agentic workflow. And talking about their workflows, the overall virtual lab appears to map to an Orchestrator-Worker agentic pattern. While the interactions (meetings) within the Virtual lab follow an Evaluator-Optimizer agentic pattern.
[II]: 🧬Evo2: Designing Entire Genome
Synthetic biologists have traditionally modified existing genomes, but AI models like the newly launched Evo 2 by NVIDIA and Arc Institute are now capable of designing entirely new genomes. Evo 2, an open-source AI model with 40 billion parameters, was trained on an extensive dataset of genetic information from over 128,000 organisms. Unlike previous models, Evo 2 can analyze and predict biological functions across genomes from various species, including humans.
One notable advancement is Evo 2's extended context window, enabling it to analyze sequences of up to one million nucleotides. This improvement allows Evo 2 to understand complex long-range genomic relationships crucial to gene regulation and chromosomal interactions, which older models could not. Its architecture, StripedHyena 2, efficiently manages long sequences by combining different convolution types to reduce computational costs.
In benchmarks, Evo 2 demonstrated impressive accuracy, predicting harmful mutations in genes like BRCA1 with over 90% accuracy, despite not training specifically on these variants. It also successfully designed genome sequences resembling human mitochondrial genomes, with AlphaFold predictions showing these generated proteins closely matched natural structures. Such capabilities suggest profound potential for precise genetic engineering, including tailored gene therapies and synthetic genome construction, marking a significant step forward in bioengineering.
[III] 🧑🔬️Google: Towards an AI Co-Scientist
Researchers have developed the AI co-scientist, an advanced multi-agent AI system designed to collaborate with scientists and accelerate breakthroughs in science and medicine. Built to address the complexity and interdisciplinary challenges of modern research, this system synthesizes vast literature, formulates novel hypotheses, and outlines viable research directions. It leverages specialized agents—supervised by a central manager—to iteratively generate, evaluate, and refine hypotheses, improving outcomes through an iterative "self-improving" feedback loop.
Practical experiments validated the AI co-scientist’s capabilities in three critical areas: identifying repurposed drugs for acute myeloid leukemia, discovering therapeutic targets for liver fibrosis, and elucidating mechanisms behind antimicrobial resistance. These successes demonstrate the system's potential to significantly accelerate and enrich scientific discovery by integrating computational reasoning with human ingenuity, ultimately paving the way for transformative biomedical and scientific breakthroughs.
[AI/LLM Engineering] 🤖🖥⚙
[I]: 🧑💻️LangGraph Functional API.
In a recent LangChain tutorial video, Lance Martin explores the advantages of LangGraph. He highlights its key benefits, including persistence, streaming, debugging, and deployment. Emphasizes that LangGraph's persistence features provide short-term memory, long-term memory, and human-in-the-loop capabilities, while its studio environment simplifies debugging and deployment.
Lance acknowledges that adopting a new framework requires learning new APIs and concepts. However, he argues that LangGraph's functional API minimizes this overhead by allowing developers to write Python code with minimal changes to leverage LangGraph's benefits. He demonstrates this by building a simple agent from scratch, first without LangGraph and then incorporating its features.
I have been playing with LangGraph for some time now but I haven't built any project with it recently. My initial thought was that the entire framework is getting messier, but the cost does have great benefits a la persistence, observability, HITL interactions, long term memory, etc.
[II]: 📄Open Deep Research
I have used Gemini & OpenAI Deep Research, and they are both really good. Geminis’ recently got an upgrade with 2.0. I am planning to incorporate a Deep Research functionality into an app idea I have, so that led me to LangChain open source implementation. For folks who don’t know, Deep Research is a popular agent use case where an agent autonomously crawls the web and produces a very detailed report on a given topic. This video discusses the various implementations of deep research, both open source and closed source, and some of the trade-offs involved. It discusses the two main themes in deep research: report planning and iterative research. The planning phase typically involves some human loop, while the iterative research phase can be done without any human intervention. The video also discusses the different architectures used in deep research, including tool calling agents and workflows. Tool calling agents are more flexible, while workflows are more reliable and often use fewer tokens. Speaking directly to the flexibility of the open source version. See implementation with Claude 3.7.
[III]: 🧠OpenAI: Prompting Reasoning Model
OpenAI has two distinct types of language models: reasoning models (the o-series) and GPT models (like GPT-4o). Here is OpenAI’s official reasoning best practices. In brief, reasoning models excel at complex problem-solving, navigating ambiguity, and making decisions based on large volumes of information. They are ideal for tasks requiring accuracy and precision, such as those in math, science, and finance. (I have found o3-mini-high to be incredibly useful for my internal use-case reasoning tasks, such as ideas generation, brainstorming, code generation/refactoring, etc) GPT models, on the other hand, are designed for straightforward execution, speed, and cost-efficiency. They are best suited for well-defined tasks where speed is more important than perfect accuracy. Many AI workflows will likely use a combination of both models, leveraging the strengths of each. According to the doc, reasoning models perform best with simple, direct prompts, and often don't require few-shot examples. When prompting these models, it is essential to be specific about the end goal and provide clear guidelines.
[IV]: 💾LangMem: Memory in LLM Applications
Here, LangChain introduced the LangMem SDK, a tool designed to help build agents that learn and adapt over time. They also shared a mental framework for leveraging memory to create more reliable and personalized agents. In the video, they break down agent memory into three types, drawing an analogy to computer information processing: semantic, procedural, and episodic. Semantic memory acts as a data store for knowledge and relationships (Like the current implementations of memory on chatGPT), procedural memory functions like code, encoding rules and behaviors (e.g. the manner in which an LLM respond to a user), and episodic memory stores past events as examples to guide the agent's responses. These memory types combined with language models enable agents to understand both what to do and how to act. Semantic memory can be represented through collections and profiles, procedural memory through system prompts, and episodic memory by learning from feedback and past experiences. More here. Code examples.
[V]: 🕵OpenAI: Agents SDK
In addition to the Agent SDK, they shared new tools for building agents with the API: Web Search, File Search, Computer Use, Responses API. Watch the full demo here. Read the announcement here.
Here are the main features of the SDK:
Agent loop: Built-in agent loop that handles calling tools, sending results to the LLM, and looping until the LLM is done.
Python-first: Use built-in language features to orchestrate and chain agents, rather than needing to learn new abstractions.
Handoffs: A powerful feature to coordinate and delegate between multiple agents.
Guardrails: Run input validations and checks in parallel to your agents, breaking early if the checks fail.
Function tools: Turn any Python function into a tool, with automatic schema generation and Pydantic-powered validation.
Tracing: Built-in tracing that lets you visualize, debug and monitor your workflows, as well as use the OpenAI suite of evaluation, fine-tuning and distillation tools.
They also gave free tracing for observability. See more Agent docs here. Demos of AI developers who have built with the Agents SDK. Here is a nice tutorial.
[AI X Industry + Products] 🤖🖥👨🏿💻
[I]: 📊 Data Science Agent in Colab
I wrote about data analysis automation in an essay over a year ago:. Here is a fairly long excerpt:
It goes without saying that data analysis and data science are an integral aspect of scientific research. And the technology available today is more than capable of automating some aspects of the scientific enterprise.
Short story: I ventured into computational biology late in grad school, partly because my biology experiments weren't progressing as quickly as I would have liked, and partly because I realized that machine learning and AI, as general-purpose technologies, would revolutionize biology and science. So, I started with reading books, taking online classes, and attending in-person classes. Simultaneously, I threw myself at various projects (I have detailed this in my PhD memoir)
Yes, AI/ML is revolutionizing many fields. However, what I couldn't have predicted then was that in the next few years, something called LLM would be able to automate some of the tasks I was learning in my machine learning class. Interestingly, the famous Transformer paper had already been published at that time.
Given the rise of tools like ChatGPT’s code interpreter (now Advanced Data Analysis), Tu et al. in their paper posed the question [1]: what should data science education do with large language models? They effectively argued that a transition somewhat akin to that from a software engineer to a product manager is inevitable for data scientists.

Today, for free, you can automate a lot of data science tasks using a data science agent in Colab. See Google’s blog about the agent. Watch a demo.
I tried it myself with a section of an ovarian cancer dataset that I have published previously. You can check out the AI data analysis notebook on my GitHub here.
[II]: 🧠GPT 4.5, Claude Sonnet 3.7, Grok 3
I used Perplexity deep research to write an article about GPT-4.5, Claude's Sonnet 3.7, and Grok 3. I eventually converted it into a page. You can find the full article here. Here is a summary:
Between February and March 2025, three advanced AI models were released, intensifying competition among top AI labs. OpenAI’s GPT-4.5, launched on February 27, prioritizes natural conversational interactions with enhanced emotional intelligence and improved factual accuracy, mathematical reasoning, and multilingual capabilities. Anthropic’s Claude Sonnet 3.7, released on February 24, introduces hybrid reasoning—combining intuitive and methodical approaches—and excels in software development due to its larger context window and specialized “Claude Code” feature, offering a more cost-effective enterprise solution. xAI’s Grok 3, released February 17-18, emphasizes computational power, advanced reasoning, and real-time information integration through X, achieving exceptional scores in scientific and mathematical domains, and primarily targets consumers via subscription-based models. This competitive landscape underscores emerging trends toward diversified AI approaches, increased user control, emphasis on real-world utility, and clear market segmentation by pricing, accessibility, and specialized capabilities. I have only used GPT 4.5 out of the three, and it’s certainly smoother vs. GPT 4o.
[III]: 💻 Manus AI
Article from Hugging Face:
In the rapidly evolving world of artificial intelligence, Manus AI is emerging as a powerful and versatile AI agent designed to automate tasks, enhance productivity, and streamline decision-making. The official website, manus.im, showcases Manus AI’s capabilities, highlighting its state-of-the-art (SOTA) performance in AI benchmarks such as GAIA. With an emphasis on real-world problem-solving, autonomous execution, and advanced tool integration, Manus AI is positioning itself as a groundbreaking solution for individuals and businesses alike …
Also, this is my favorite demo of Manus AI. Rough at the edges, but unsurprising for a product in private beta. (For folks who still don't get what the future of working with AI looks like, this is also a fine demo to watch.)
[IV]: 💬 Eleven Labs: Speech to Text Scribe v1
The ElevenLabs Speech to Text (STT) API turns spoken audio into text with state of the art accuracy. Our Scribe v1 model adapts to textual cues across 99 languages and multiple voice styles and can be used to:
- Transcribe podcasts, interviews, and other audio or video content
- Generate transcripts for meetings and other audio or video recordings
The Scribe v1 model is capable of transcribing audio from up to 32 speakers with high accuracy. Optionally it can also transcribe audio events like laughter, applause, and other non-speech sounds.
The transcribed output supports exact timestamps for each word and audio event, plus diarization to identify the speaker for each word.
The Scribe v1 model is best used for when high-accuracy transcription is required rather than real-time transcription. A low-latency, real-time version will be released soon.
Read the full doc here, See a demo (transcribing one of the fastest rap song of all time)
[V]: ⚡️ Bolt: Figma to Code
Introducing Figma to Bolt
Go from Figma to pixel-perfect full stack app — just put bolt․new in front of the URL & start prompting!
To get started, go to http://bolt.new and click "Import Figma" and paste the frame's URL. Everyone gets 3 free conversions/mo & after that uses tokens (50-200k, depending on size).💡 For the best results, use Auto Layout in your Figma designs!
[AI + Commentary] 📝🤖📰
[I]: 💵ChatGPT Prompt to Billion Dollar Companies.
Rex Woodbury's article discusses the burgeoning market for effective ChatGPT prompts, highlighting their potential to become a million/billion-dollar industry. He argues that as AI models like ChatGPT become more integrated into daily workflows, the ability to craft precise and efficient prompts will be a highly valued skill. Woodbury likens this to the early days of search engines, where understanding how to formulate effective queries was crucial.
The article explores how prompts are evolving from simple questions to complex, multi-layered instructions that can generate sophisticated outputs. Woodbury discusses the emergence of prompt marketplaces and the growing demand for specialized prompts tailored to specific industries and tasks. He emphasizes that the value lies not just in the prompts themselves, but in the expertise and creativity required to develop them. In essence, the unbundling of chatGPT, with good prompt engineering. “Each prompt could be its own app, which would actually be a better user experience: seamless onboarding, elegant design, app notifications.”
[II]: 💲Anthropic Economic Index
The Anthropic Economic Index explores the impact of AI systems on labor markets and the economy. Using millions of anonymized conversations from Claude.ai, Anthropic has compiled data revealing how AI is currently integrated into real-world tasks. The report highlights that AI usage is primarily concentrated in software development and technical writing, with over a third of occupations utilizing AI for at least a quarter of their tasks. Furthermore, the research indicates a greater emphasis on AI augmentation (collaborating with and enhancing human capabilities) rather than pure automation (AI directly performing tasks). Interestingly, AI use is more prevalent in mid-to-high wage occupations.
The study, as explained by Anthropic, utilizes a novel approach by analyzing occupational tasks rather than entire occupations. This allows for a more granular understanding of AI integration, recognizing that jobs often share common tasks. Using their automated analysis tool, "Clio," Anthropic matched conversations with Claude to tasks defined by the U.S. Department of Labor's O*NET database. This methodology allowed them to map AI usage across various occupations and categories, revealing that computer and mathematical fields (especially software engineering) see the highest AI adoption rates. Anthropic acknowledges certain limitations to their study, such as the inability to definitively determine if Claude usage was for work purposes and the potential for misclassification of tasks by Clio. Despite these caveats, the Anthropic Economic Index represents a significant step towards understanding AI's evolving role in the labor market.
[III]: 🍎AI eating Startup World.
The venture capital world is experiencing an AI-driven boom, with a staggering $110 billion invested in AI startups globally last year. This figure represents approximately 33% of all venture capital investments, signaling a massive influx of capital into the sector. This surge isn't confined to established players; even early-stage startups are incorporating AI into their business models to attract funding. Data from Y Combinator reveals the pervasiveness of this trend, showing that around 80% of companies in their directory now feature "AI" in their name or description, a dramatic increase from just 15% five years ago.
Despite the excitement, the authors caution about the inherent risks of VC investing. While some AI companies will undoubtedly achieve substantial success, the reality is that many will likely fail. The example of Inflection AI, which folded its generative AI business despite raising $1.5 billion, serves as a reminder of these risks. The article highlights the uncertainty surrounding the future of AI and its impact on established businesses. It raises questions about who will ultimately benefit most from the AI revolution – whether it's infrastructure providers, foundational model creators, or companies integrating AI into their products. The potential for disruption is also explored, using the example of Duolingo and its potential vulnerability to AI-powered language translation.
[IV]: 🇨🇳The Political Economy of Manus AI.
In a recent analysis, Tyler Cowen discusses the implications of Manus potentially outpacing its American counterparts. The core concern revolves around the potential for Chinese AI to access and operate within American computer systems. While government restrictions may limit official use, Cowen acknowledges that private use will likely be widespread. This raises concerns about data accessibility for the Chinese Communist Party (CCP) and the potential for information capture, especially within sensitive sectors like finance and military-adjacent networks.
Cowen also explores the reciprocal impact on China, suggesting that the proliferation of agentic AI could fundamentally alter the CCP's role and authority. With AI systems operating on diverse datasets, the CCP's traditionally centralized control may erode, leading to a new "spontaneous order" where AI influences governance. The question arises: does the CCP recognize this potential shift, and if so, how will they respond? Cowen posits that the competitive nature of AI development might favor systems aligned with "universal knowledge" over dogmatic control, potentially reshaping the very essence of Chinese political power. Ultimately, Cowen prompts reflection on the broader consequences of this technological advancement. The analysis urges readers to consider who stands to gain or lose in this emerging equilibrium, questioning whether the potential benefits of advanced AI outweigh the risks of diminished control and altered power dynamics.
[V]: ✌️ On Vibe Coding
Andrew Chen explores the emerging concept of "vibe coding," a paradigm shift where AI-powered tools enable rapid software development through natural language prompts. He highlights Andrej Karpathy's observation that LLMs are becoming so adept at code generation that developers can essentially "vibe code," relying on AI to handle much of the technical work. Chen predicts this trend will democratize software creation, potentially leading to a surge in youth-driven software and a move away from traditional open-source libraries as AI generates personalized code on demand.
Chen also anticipates significant changes in software development workflows, with a potential shift from CLI-based coding to visual-based "vibe designing." He suggests that the focus will move from writing code to defining desired outcomes, with AI adapting software based on user behavior. Furthermore, he discusses the potential impact on software development teams, marketing, and the emergence of new challenges related to bugs, security, and the handling of edge cases. Despite the current limitations of vibe-coded applications, Chen believes that the technology's rapid advancement will soon enable the creation of highly sophisticated and personalized software experiences, mirroring the evolution of AI-generated images and videos.
Finally, Chen provides insight into how vibe coding is currently being implemented, referencing NicolasZu's flight simulator project as an example of building complex applications. NicolasZu's methodology.
From YC’s Lightcone:
[VI]: 📱The AI-Driven Dismantling of SaaS
In this long tweet, Greg Isenberg argues that the traditional SaaS model, valued at $1.3 trillion, is facing a fundamental disruption driven by the rapid advancement of AI agents. Currently, we're in a phase where AI acts as a "co-pilot," enhancing existing software functionality, as seen with tools like Copilot for developers and Gamma for presentations. However, Isenberg predicts that within the next 12-18 months, AI will transition to autonomous operation, becoming "replacement workers" that can fully manage software tasks (the writing seems to be on the wall with products like Manus and OpenAI’s operator). This shift will unbundle the expertise previously tied to software interfaces, allowing users to execute complex tasks with simple AI commands.
In the final phase, projected within 2-3 years, Isenberg envisions "software invisibility," where AI agents bypass human interfaces entirely, accessing software capabilities directly through APIs. This eliminates the need for user-friendly dashboards and menus, undermining the core value proposition of SaaS. Simultaneously, the barrier to creating custom software is collapsing, empowering companies to build bespoke solutions with AI coding assistants. This democratization of software creation means that businesses can tailor software to their specific needs, reducing reliance on expensive, off-the-shelf SaaS subscriptions. Isenberg suggests that the winners in this evolving landscape will be companies that prioritize agent-friendly APIs and establish themselves as trusted information and execution engines, rather than focusing solely on feature enhancements. Given the current rates of change, all of this sounds correct to me, or I should say that it is the optimistic take for the penetration of AI into software.
[X] 🎙 Podcast on AI and GenAI
(Additional) podcast episodes I listened to over the past few weeks:
Please share this newsletter with your friends and network if you found it informative!