


Brief Notes on LCEL
LangChain Expression Language.

I attempted to explain some keywords as I write this article, however, I quickly figured explaining everything ‘new’ will be impossible for a piece of the length I would like to write. As such I decided to do things the traditional way - glossary. If any term is new to you or couldn’t figure out what something means by reading the text, head to the glossary at the end of this piece.
Supplementary code for Brief Notes on LCEL.
Introduction
LangChain Expression Language, or LCEL, as it is called, is a declarative framework that simplifies the composition of complex chains.
It prioritizes ease of use and scalability making the language especially suitable for production environments.
There are many things to say about what I have just said, but I suppose a few details are in order (and we can delve deeper into the significance of the language as we unpack its anatomy further into this piece):
LCEL enables efficient streaming of outputs from language models to parsers. This feature allows for incremental parsing of output in real time (If you have used chatGPT then you know what streaming is).
Chains constructed using LCEL can operate both synchronously (say within your favorite IDE when prototyping) and asynchronously (e.g., on production servers). This dual capability facilitates the use of a consistent codebase throughout various development and deployment stages.
LCEL is designed to automatically execute steps within a chain that are capable of parallelization concurrently. This reduces latency.
LCEL provides mechanisms for configuring retries and fallbacks for certain parts of a chain, thus enhancing the system's reliability at scale.
That’s enough for an introduction, let’s get a chain running.
Chains
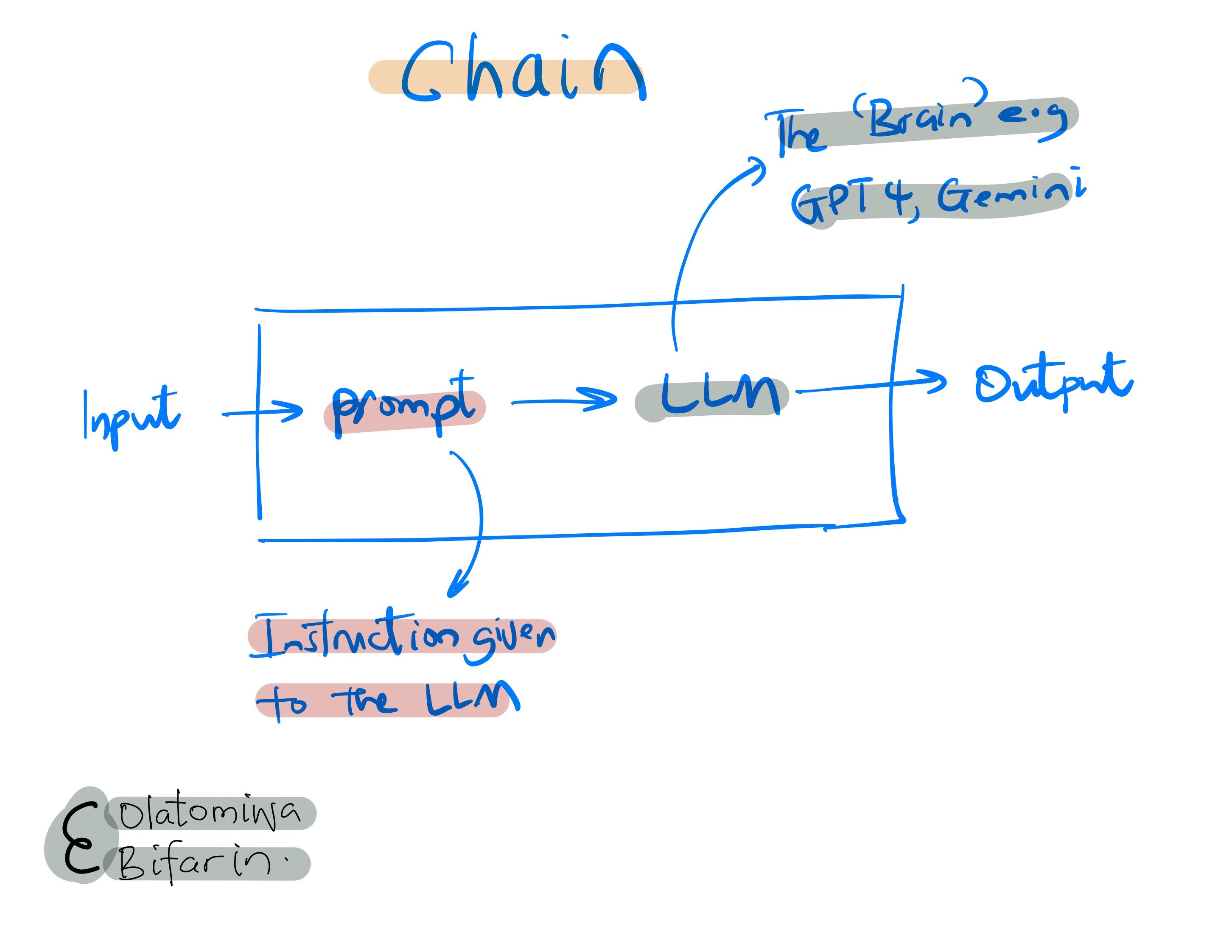
And that is a simple chain, we pass a prompt into a LLM, and get our output.
What does the LCEL of that chain look like?
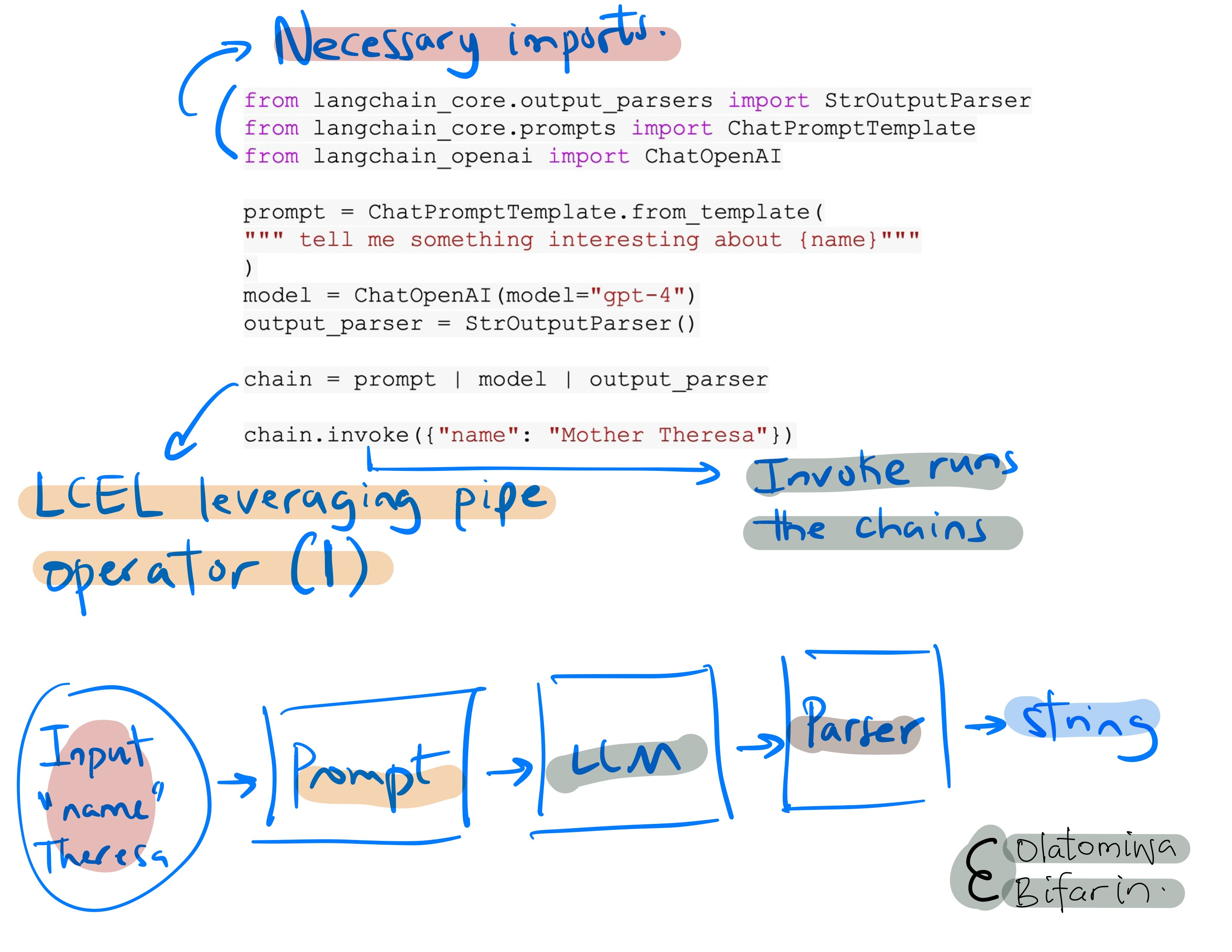
So, breaking this down, this chain has 3 components:
chain = prompt | model | output_parserWe have a prompt “tell me something interesting about {name}”, the LLM we are using is GPT-4, and a string output parser (StrOutputParser), to parse the string output.
Notice the pipe operator ( | ), which is a signature of the LCEL. In brief, it denotes piping the operation/entity on the left to the right operation/entity. So in this case, our prompt goes into the model and the model’s output goes into the output parser.
Let’s look at another simple but slightly more complicated use case: Retrieval Augmented Generation (RAG)

First we set up a vector store for RAG, in this case we use DocArray InMemorySearch, a document index.
vectorstore = DocArrayInMemorySearch.from_texts(
["Bifarin is a post-doc at Georgia Tech",
"Edward III was the King of England from 1327 to 1377"],
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()Our text prompt will take in as input two entries: {context} and {question}.
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)Because we are now having this slightly more complicated example, we need to set up our retriever system before passing it into the prompt. And we will do that using Runnable Methods.
Perhaps we should start by asking what Runnables are. Runnables are the building blocks of LangChain (Runnable protocol is implemented for components in LangChain). They are functions designed for parallel execution and are capable of intercommunication via events.
And how do they differ from chains?
Chains are structured from (runnable) components and establish the sequence of their execution (as we have already seen). Chains enable the construction of complex workflows, facilitating their execution in just a singular step.
The primary distinction between runnables and chains though, lies in their functional roles: runnables serve as the discrete units of execution, whereas chains orchestrate the execution process of these runnables according to a predefined workflow.
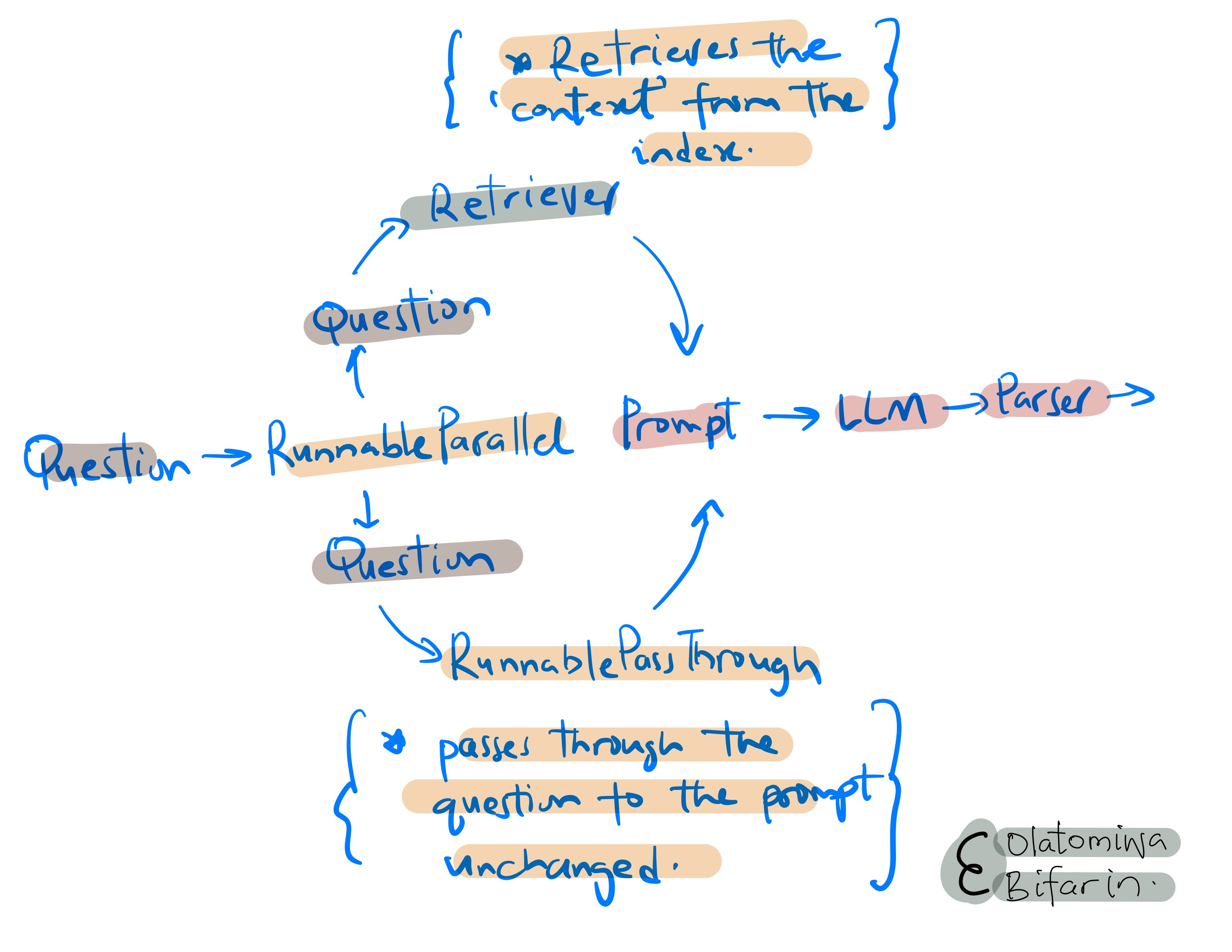
Back to our code: “we need to set up our retriever system before passing it into the prompt. And we do that using Runnable Methods.” In other words, again, we can create components of chains using Runnable methods.
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()})In this case we are using two methods: RunnableParallel() and RunnablePassthrough(). The former, also known as RunnableMap, allows us to run Runnable maps in parallel (note that the prompt takes in a map with keys “context” and “question”), in general it allow for the manipulation of data such that the a Runnable’s output match the input format for the next Runnable in line; while the latter, allows for the transmission of inputs in their original form or augmented with additional keys: in this case it passes the user’s question to the prompt and the model, in its original form.
Interface
Now we know what a LCEL chain is, we can then proceed to interface; (but at the risk of repeating myself, a LCEL chain is a series of components, stitched together by pipe operators, creating a sequence of operations that does a kind, or series of transformations.)
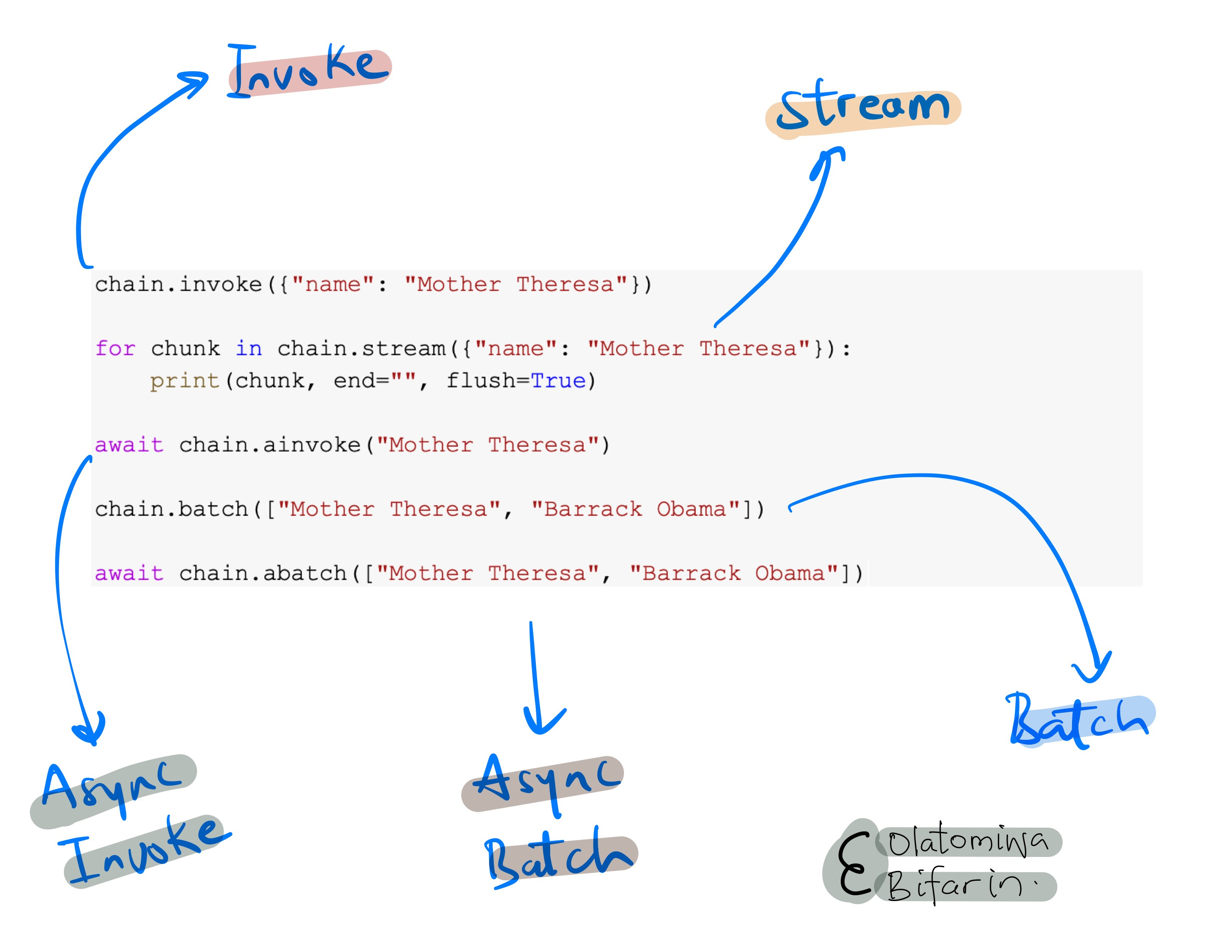
As for interface, one of them is invoke. As seen in one of the previous examples (chain.invoke), once a chain is constructed, invoking it carries out the defined sequence of operations within the chain, channeling any required input data through the sequence to yield the final outcome.
And instead of just merely invoking a chain, you can invoke it by using the stream interface, which will allow the system to stream the output of the LLM one word at a time, say.
Batch: you can batch multiple inputs and run them in parallel.
Async: Allows for the asynchronous execution of code, with corresponding async methods for the interface highlighted above: astream, ainvoke, abatch.
There are many things to say and learn about LCEL. However, this is only meant to be a note that could get you started. LangChain has been doing a great job recently at cleaning up their documentations.
So you can continue at the official entry on LangChain.
Glossary
Asynchronous Execution: A non-linear, concurrent method that allows steps in a chain to run simultaneously, improving efficiency for complex tasks.
Chain: A sequence of components connected by pipe operators (|) that define a series of operations for data transformation.
Component: Individual units within a chain that perform specific operations or transformations on data, such as Prompt, ChatModel, LLM, OutputParser, Retriever, Tool, etc.
Interface: The means by which chains are executed, including methods for invocation, streaming, batching, and asynchronous execution.
Latency: The delay between the initiation and completion of a process, which parallelization aims to reduce.
Parallelization: The ability to execute multiple steps or tasks concurrently to reduce latency and increase efficiency.
Parser: A component that interprets and transforms the output of a language model into a desired format.
Pipe Operator (|): A symbol used to denote the flow of data from one component to another within a chain.
Retries and Fallbacks: Mechanisms for re-attempting operations that fail and providing alternative actions if the initial operation cannot be completed.
Retrieval Augmented Generation (RAG): A technique that combines retrieval of relevant documents with language generation to produce contextually accurate responses.
Streaming: The process of transmitting data in a continuous flow, allowing for real-time processing and incremental parsing of outputs.
Synchronous Execution: A linear, blocking method where each step in a chain waits for the previous one to complete before proceeding.
Vector Store: A storage system used for indexing and retrieving documents based on vector embeddings.